Video matting aims to predict the alpha mattes for each frame from a given input video sequence.
Recent solutions to video matting have been dominated by deep convolutional neural networks (CNN)
for the past few years, which has become the de-facto standard for both academia and industry.
However, they have inbuilt inductive bias of locality and do not capture global characteristics of an image
due to the CNN-based architectures. They also lack long range temporal modeling considering computational costs
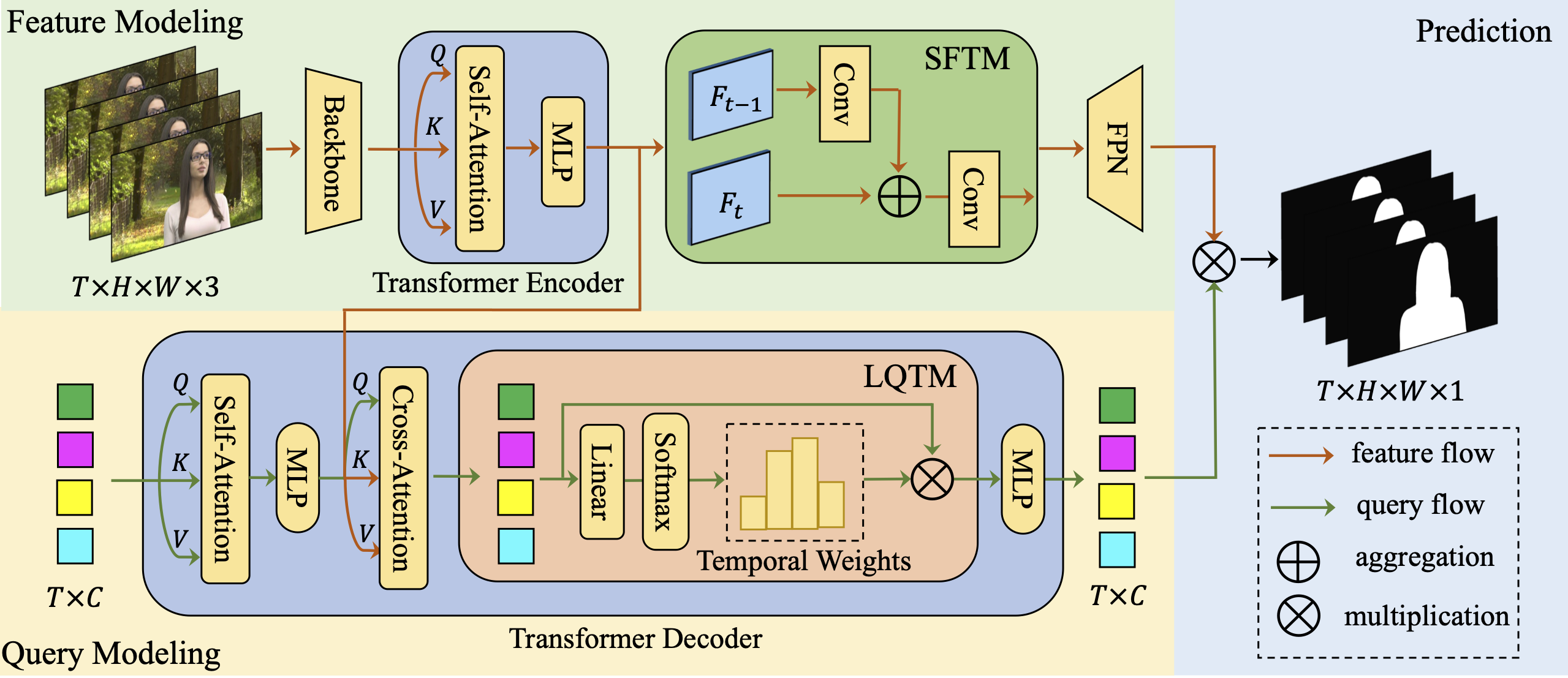
when dealing with feature maps of multiple frames. In this paper, we propose VMFormer: a transformer-based
end-to-end method for video matting. It makes predictions on alpha mattes of each frame from learnable queries given
a video input sequence. Specifically, it leverages self-attention layers to build global integration of feature sequences
with short-range temporal modeling on successive frames. We further apply queries to learn global representations
through cross-attention in the transformer decoder with long-range temporal modeling upon all queries.
In the prediction stage, both queries and corresponding feature maps are used to make the final prediction of alpha matte.
Experiments show that VMFormer outperforms previous CNN-based video matting methods on the composited benchmarks.
To our best knowledge, it is the first end-to-end video matting solution built upon a full vision transformer with
predictions on the learnable queries.