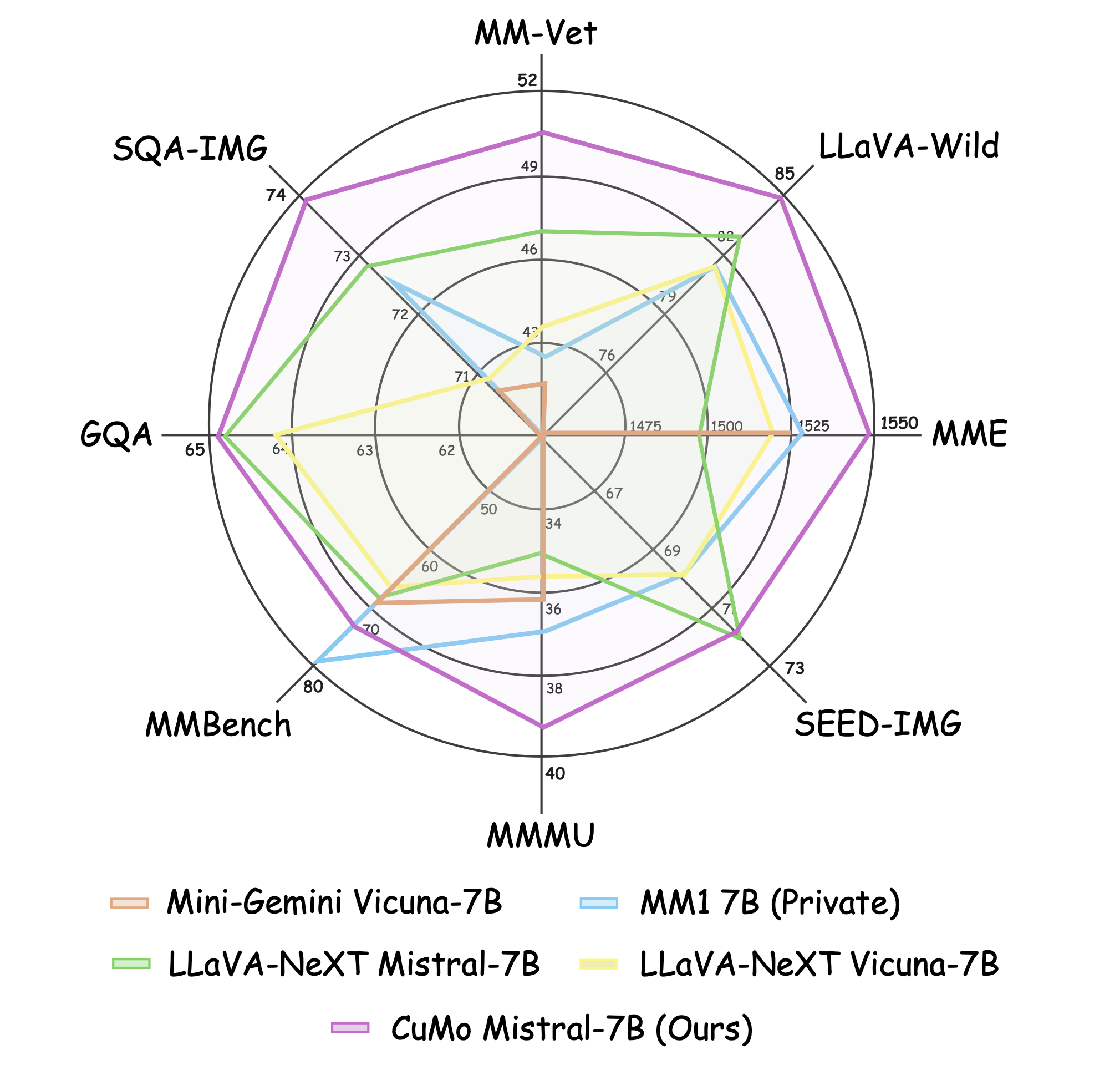
Recent advancements in Multimodal Large Language Models (LLMs) have focused primarily on scaling by increasing text-image pair data and enhancing LLMs to improve performance on multimodal tasks. However, these scaling approaches are computationally expensive and overlook the significance of improving model capabilities from the vision side. Inspired by the successful applications of Mixture-of-Experts (MoE) in LLMs, which improves model scalability during training while keeping inference costs similar to those of smaller models, we propose CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into both the vision encoder and the MLP connector, thereby enhancing the multimodal LLMs with neglectable additional activated parameters during inference. CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage, with auxiliary losses to ensure balanced loading of experts. CuMo outperforms state-of-the-art multimodal LLMs across various VQA and visual-instruction-following benchmarks within each model size group under training exclusively on open-sourced datasets.
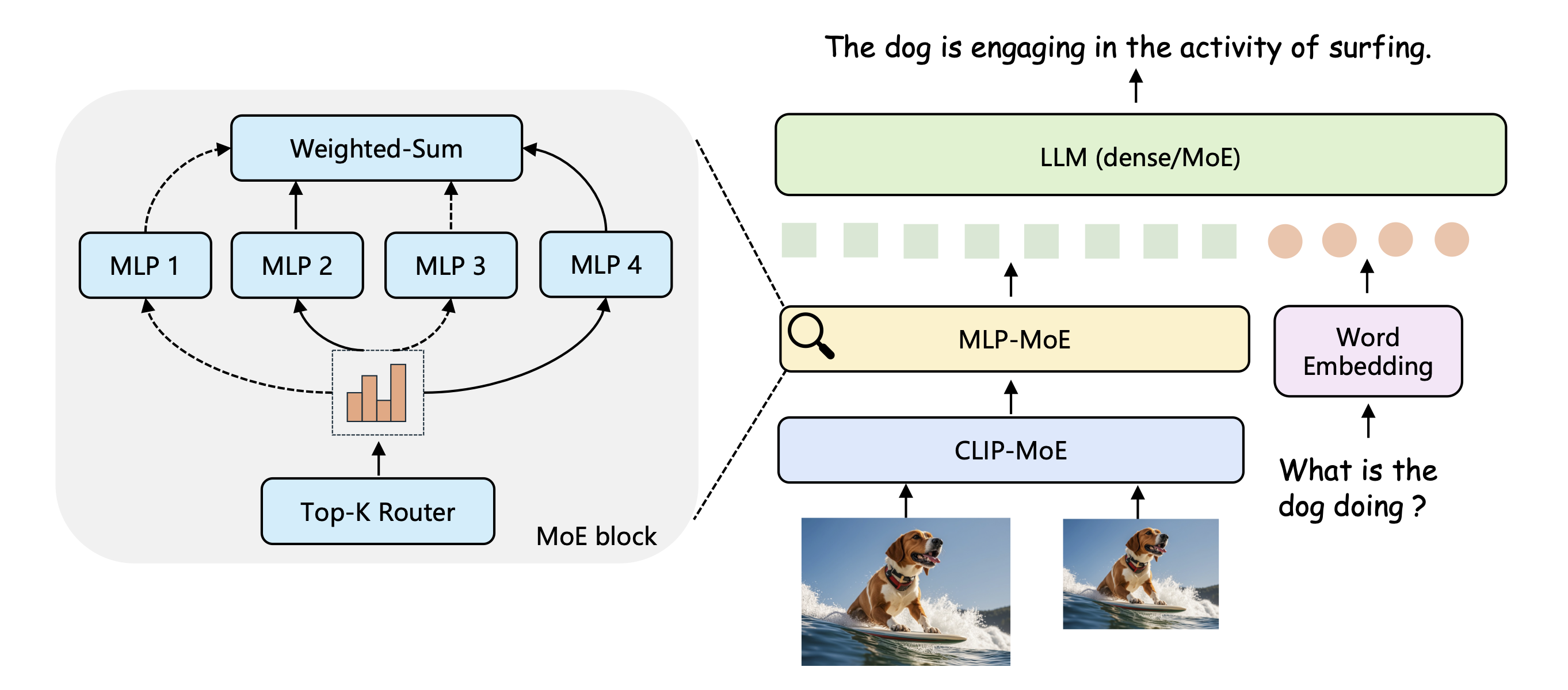
CuMo incorporates sparse Top-K MoE blocks into the CLIP vision encoder and vision-language MLP connector, thereby improving the multimodal LLM capabilities from the vision side. Skip connections are omitted for simplicity. Further implementation details are provided in Section 3.2.
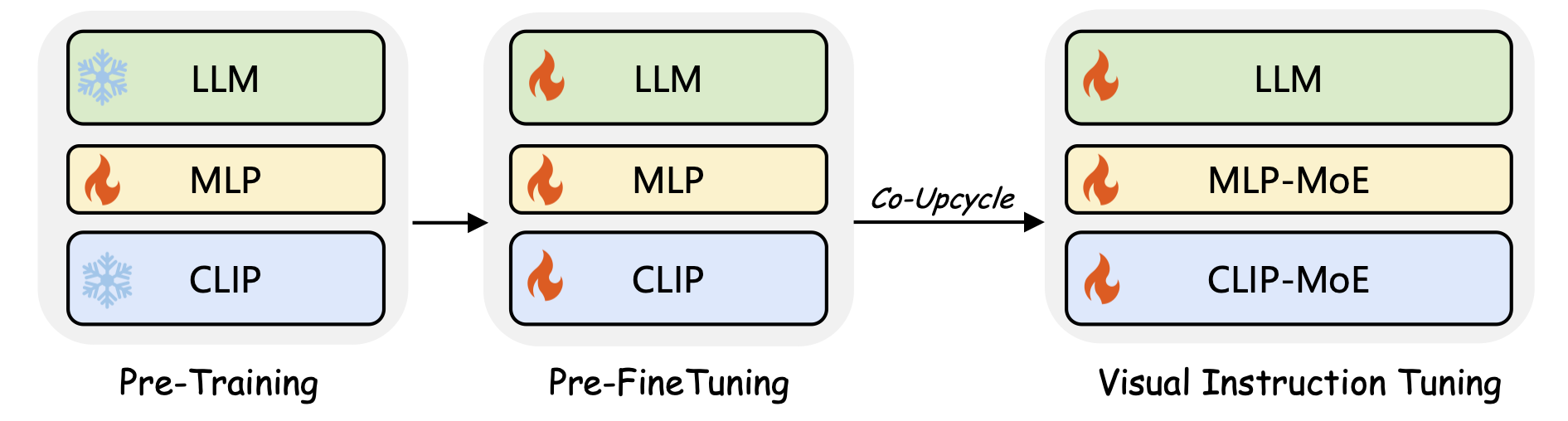
Training Stages of CuMo models. The first stage involves pre-training the MLP for better alignment. Subsequently, the pre-finetuning stage trains all parameters as a warm-up before the next stage. Finally, the MLP experts within each MoE block are initialized from the weights of the corresponding MLP block, followed by training all parameters in the visual instruction tuning stage

Dialogues between the user and multimodal LLMs on challenging images. We highlight the correct answers and hallucinations from the responses of the multimodal LLMs.